starrocks CBO优化器
一条SQL的执行的流程会经过词法分析 语法分析, 查询优化,查询执行,存储。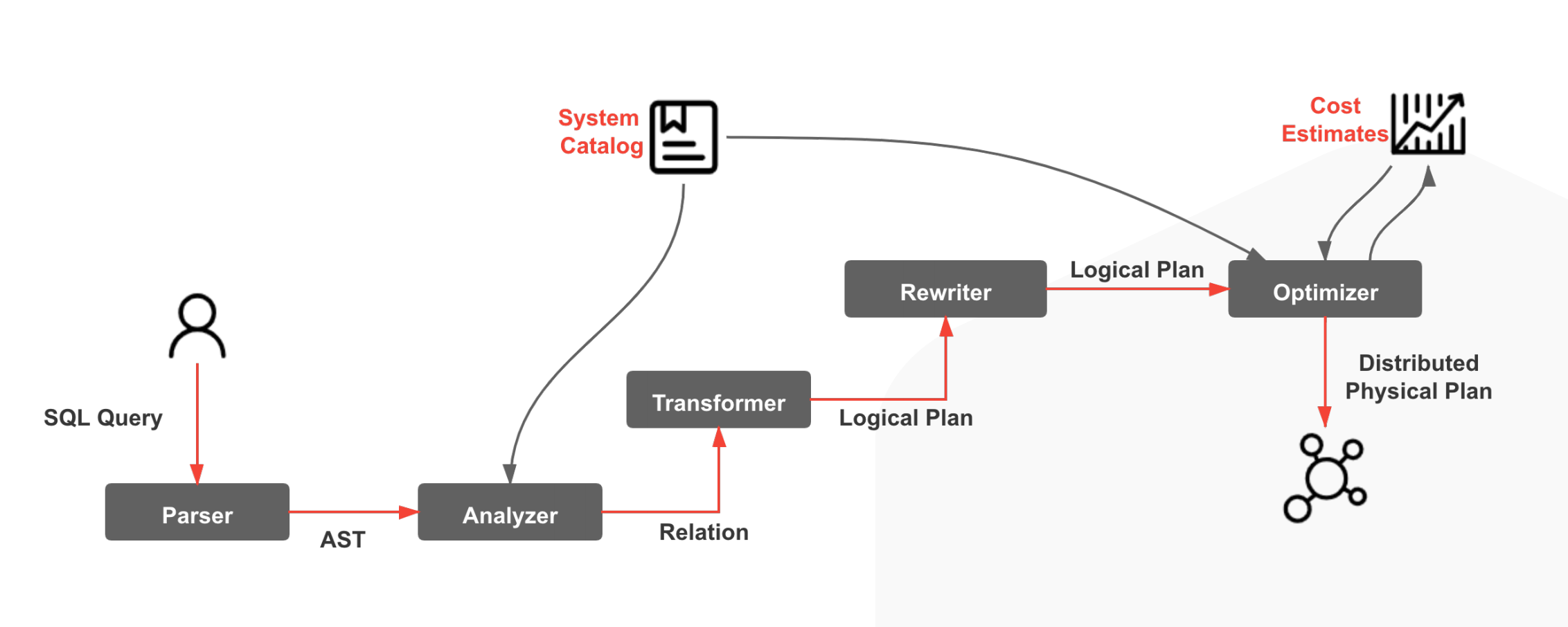
在starrocks 的优化器中首先将loginplan转换为memo的数据结构,然后基于 实现的规则Rule 将 Logical Group Expression 转换成 Physical Group Expression,基于统计信息和 Cost 估计从 Memo 中选择一组 Cost 最低的 Physical Group Expressions,最后将选择的 Physical Group Expressions 转成 Physical Plan tree。
insert query的调用方法如下:
OptExpression optimizedPlan = optimizer.optimize(
session,
logicalPlan.getRoot(),
new PhysicalPropertySet(),
new ColumnRefSet(logicalPlan.getOutputColumn()),
columnRefFactory);optimze实现的流程如下:
1 memo.init(logicOperatorTree); 将逻辑操作树转换为GroupExpression
2 logicalRuleRewrite(memo, rootTaskContext); 将groupExpression 基于规则进行重写
3 memoOptimize(connectContext, memo, rootTaskContext); 针对memo 进行优化
4 physicalRuleRewrite(rootTaskContext, result); 基于物理规则重新执行计划
public OptExpression optimize(ConnectContext connectContext,
OptExpression logicOperatorTree,
PhysicalPropertySet requiredProperty,
ColumnRefSet requiredColumns,
ColumnRefFactory columnRefFactory) {
Memo memo = new Memo();
....memo init
memo init是将logic plan转变为groupExpress
Memo memo = new Memo();
memo.init(logicOperatorTree);
->
GroupExpression rootGroupExpression = copyIn(null, originExpression).second;Memo 的初始化会从 LogicalPlan 的 根OptExpression 出发,递归地调用copyIn方法,将OptExpression封装为GroupExpression,每一个GroupExpression会单独添加到一个Group中
public Pair<Boolean, GroupExpression> copyIn(Group targetGroup, OptExpression expression) {
List<Group> inputs = Lists.newArrayList();
for (OptExpression input : expression.getInputs()) {
Group group;
if (input.getGroupExpression() != null) {
group = input.getGroupExpression().getGroup();
} else {
// 若当前OptExpression的inputOptExpression还未封装为Group,则递归地封装inputOptExpression
group = copyIn(null, input).second.getGroup();
}
...
inputs.add(group);
}
GroupExpression groupExpression = new GroupExpression(expression.getOp(), inputs);
Pair<Boolean, GroupExpression> result = insertGroupExpression(groupExpression, targetGroup);
...
return result;
}例子
Student(id, name, sex, age)
selection(sid, cid, grade)
course(id, name, teacher)
-------------------------------------
select s.id, s.name, c.name, sc.grade
from student s, selection sc, course c
where s.id=sc.sid and sc.cid=c.id and sc.grade>90 and s.name='tom'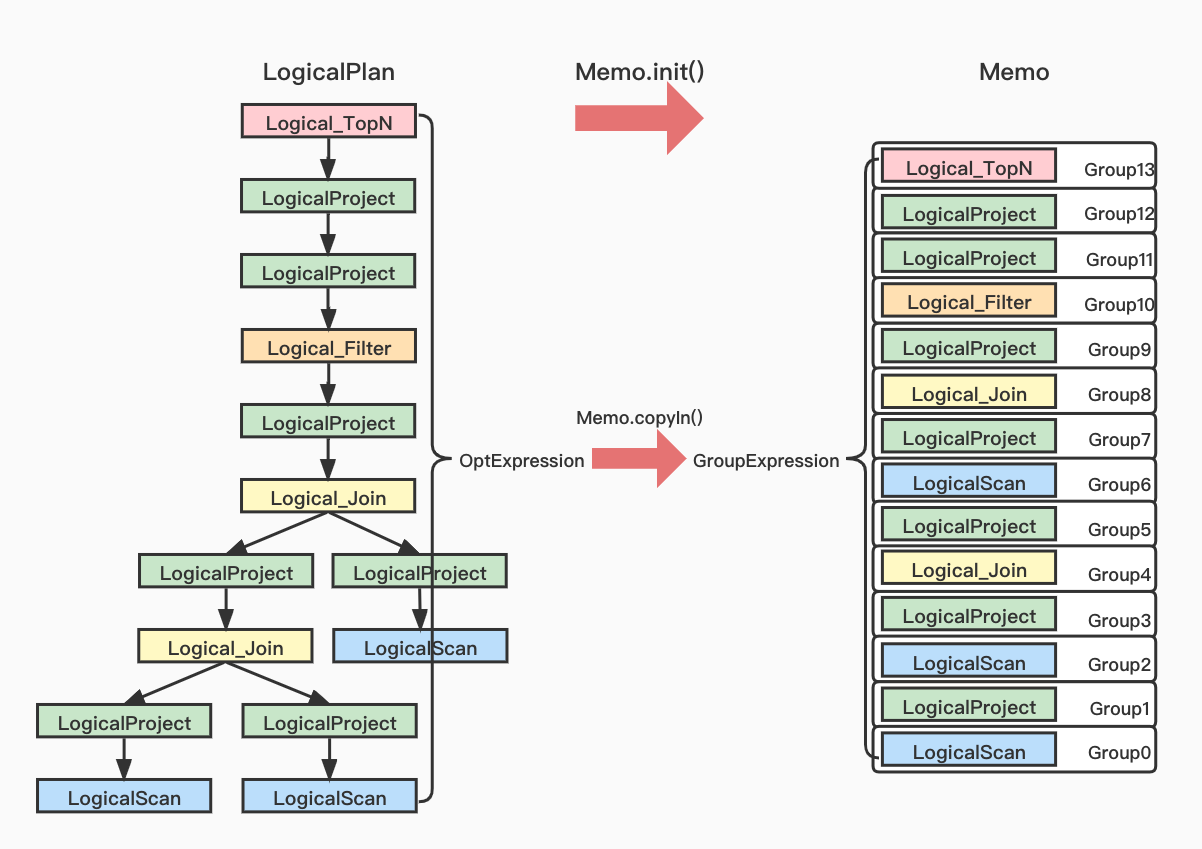
Rewrite 基于规则重写
主要完成了:
各种表达式的重写和化简,如:CTE 重写
列裁剪
谓词下推
Limit 下推
等价谓词推导(常量传播)
Outer Join 转 Inner Join
常量折叠
公共表达式复用
子查询重写
Lateral Join 化简
分区分桶裁剪
Empty Node 优化
void logicalRuleRewrite(Memo memo, TaskContext rootTaskContext) {
...
// 清除空的或不可达的Group
cleanUpMemoGroup(memo);
...
// 谓词下推
ruleRewriteIterative(memo, rootTaskContext, RuleSetType.PUSH_DOWN_PREDICATE);
...
// 合并两个连续的Project操作
ruleRewriteIterative(memo, rootTaskContext, new MergeTwoProjectRule());
...
// 将Project操作合并到子操作中
ruleRewriteIterative(memo, rootTaskContext, new MergeProjectWithChildRule());
...
}Rewrite Task 的驱动在 Optimizer类 ,各种 Rewrite的Rule在 rewrite 目录
Student(id, name, sex, age)
selection(sid, cid, grade)
course(id, name, teacher)
-------------------------------------
select s.id, s.name, c.name, sc.grade
from student s, selection sc, course c
where s.id=sc.sid and sc.cid=c.id and sc.grade>90 and s.name='tom'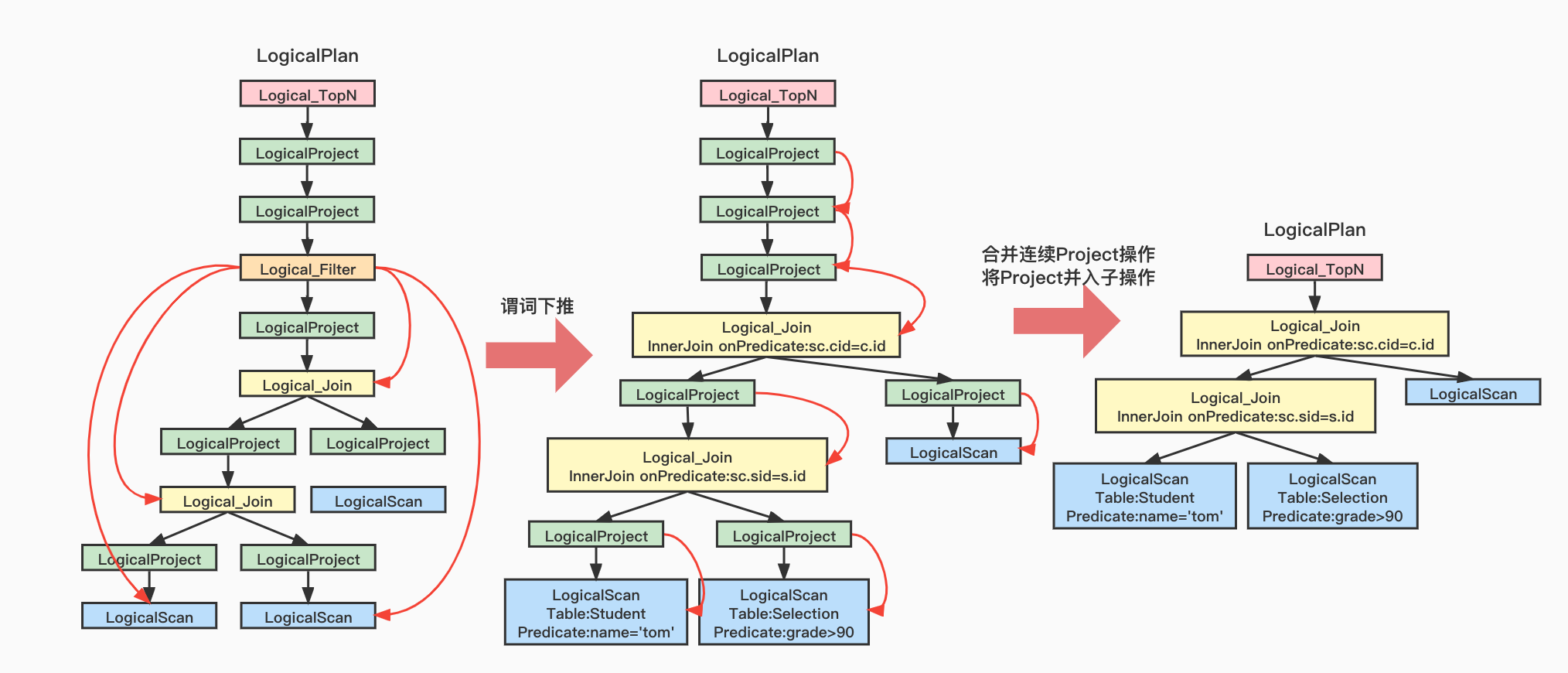
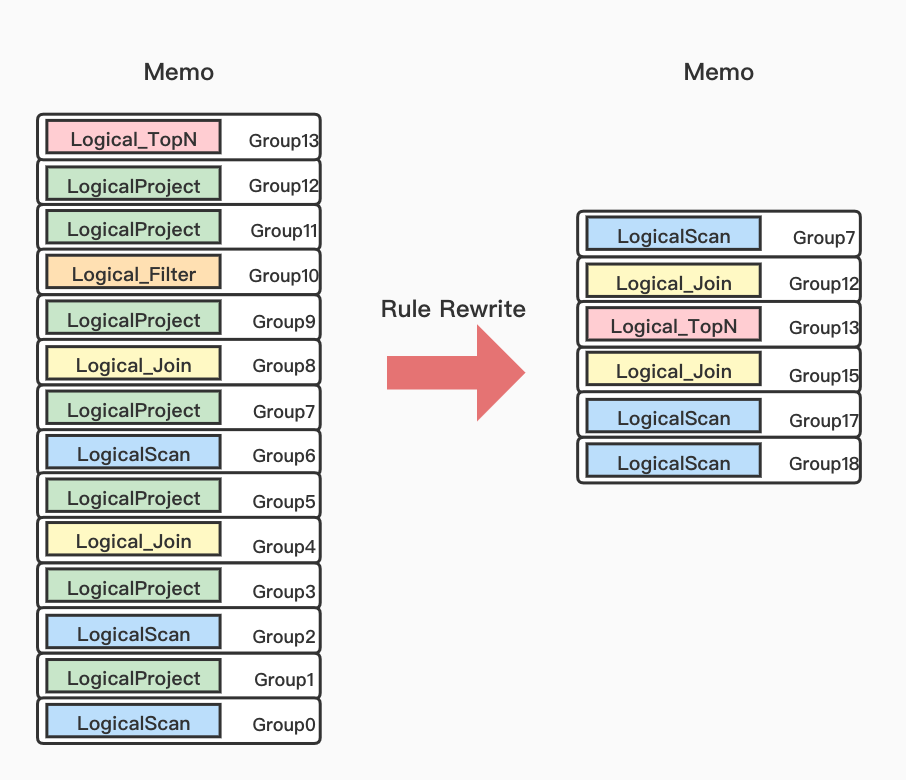
CBO重写
在 Rewrite 完成后,正式基于 Columbia 论文进行 CBO 优化,主要包括下面的优化:
两阶段聚合优化
Join 左右表调整: StarRocks 是用永远用右表构建 Hash 表,所以右表应该是小表,StarRocks 可以基于 cost 自动调整左右表顺序,也会自动把 left join 转 right join。
Join 多表 Reorder:多表Join 如何选择出正确的Join 顺序,是优化器的核心,当Join表的数量小于等于5时,StarRocks 会基于Join 交换律和结合律进行 Join Reorder,大于5时,StarRocks 会基于贪心算法 和动态规划进行 Join Reorder。
Join 分布式执行选择:StarRocks 支持地分布式Join 方式有Broadcast,Shuffle, 单边 Shuffle,Colocate,Replicated。StarRocks 会基于 Cost 估算 和 Property Enforce 机制选择出 “最佳” 的 Join 分布式执行方式
Push Down Aggregate to Join
物化视图选择与重写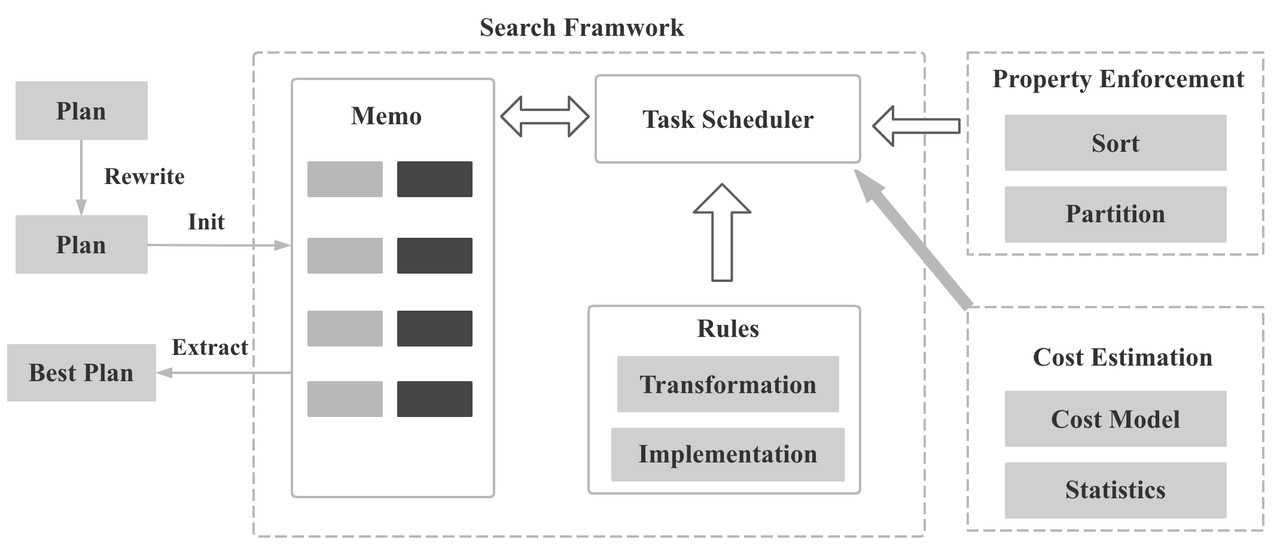
CBO统计
Cost 估算的基础是统计信息估算,统计信息估算的基础是统计信息收集。 StarRocks 目前支持表级别和列级别的统计信息,支持自动收集和手动收集两种方式,无论自动还是手动,都支持全量收集和抽样收集两种方式。
StarRocks 统计信息收集内容和收集框架如下图所示。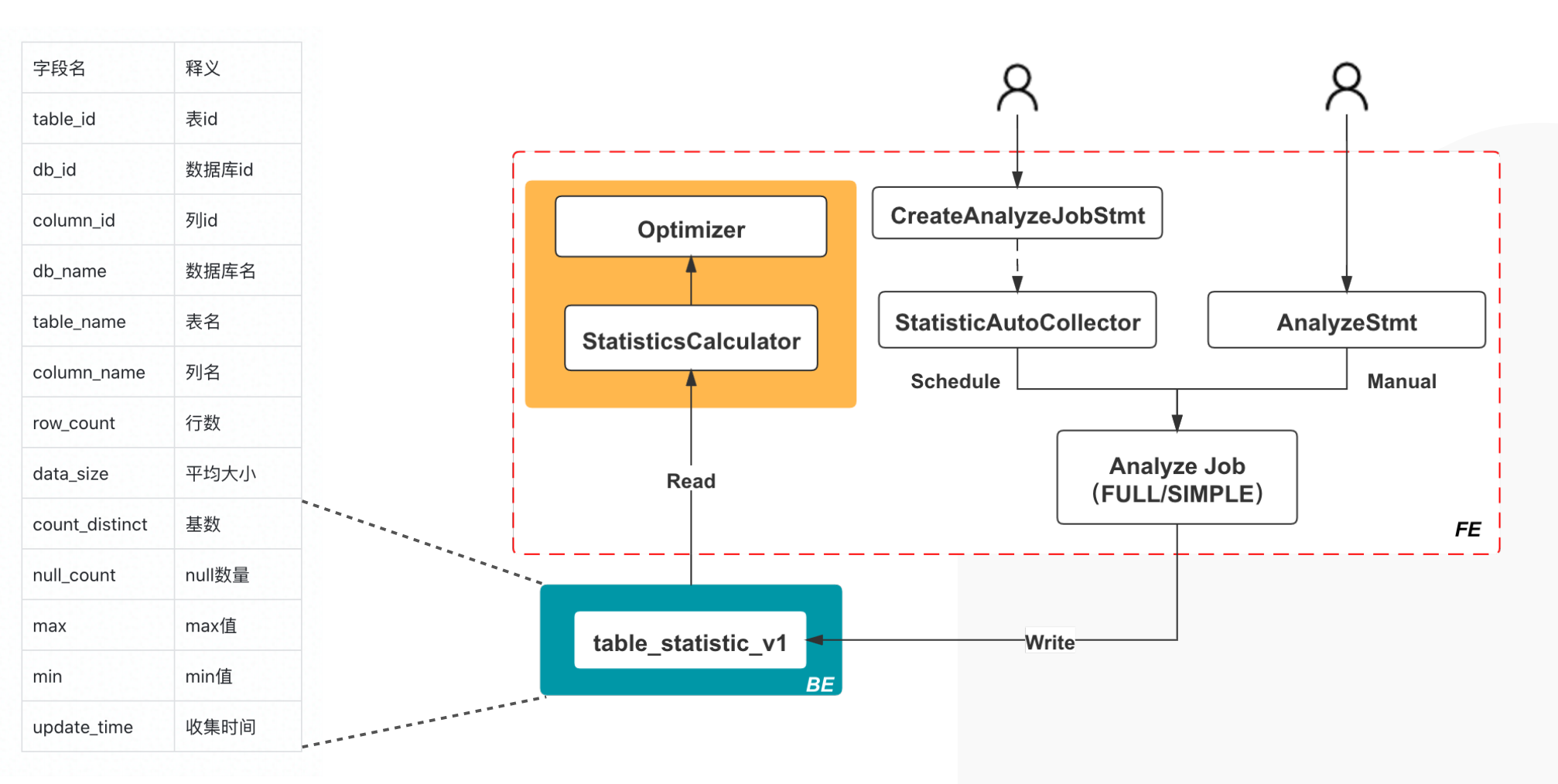
StarRocks 统计信息收集的代码位于 statistic
cost 计算
统计信息估算和 Cost 估算是整个 CBO 优化器最关键的部分之一,其中每一个公式和系数的改动,都会对最终的 Plan 产生很大的影响,这一块也是业界一直在研究的热点,统计信息估算和 Cost 估算的难点体现在下面几个方面:
数据分布不是完全均匀的
多列之间的数据特征不是完全独立的
一些函数和复杂表达式的选择率无法较好地估计
基于多个维表的谓词去估算事实表的基数时,很难估算准
基数估计的误差会被层层放大
统计信息估算和 Cost 估算 的代码 位于 statistic 目录 和 cost 目录 下
如何优化搜索耗时
提前 Rewrite (预处理):在进入优化阶段之前,对表达式 进行 Rewrite, 对整个Plan 进行 肯定会变优的Rewrite,降低优化时的搜索空间大小
Multi-Stage Optimization:分多个Stage 进行优化,每个Stage 只应用部分Rule,越复杂的Rule 应用地越靠后
按需 Explore group:Logical transformation 和 Physical implementation 不会分两阶段执行,对于一个 Group,不必生成完所有的逻辑表达式。通过transformation rule 生成的逻辑表达式 会立即被 implemented 成物理表达式并计算 cost。这种实现方式可以基于 Cost 进行快速裁剪,避免枚举低效的 Plan。 例如,我们计算 ((A join B join C) join D) 的 cost, 如果 先 ((A join B join C) , 再 join D 的 cost 已经大于了 ((A join B) join (C join D)) 的cost, 我们就可以进行快速裁剪,避免对 (A join B join C) 进行 join order 的枚举。
Upper bounds Pruning: 如果当前 Group 的 lower bound 大于当前 context的 UpperBound,我们就没有必要继续enumerated 当前 Group 的 input groups
记忆化: 利用 Bitmap 去重,保证一个Group 不会用同一个Rule重复优化
Group 支持删除(替换): 如果经过 Transform Rule 后生成的新Group Expression 一定比旧的好,我们可以把旧的Group Expression 从Group 删除,或者使用新的Group Expression 直接替换掉旧的 Group Expression,这样可以降低搜索空间的大小
Multi Join Reorder: 多张表Join reorder 时,按照Multi-Join 或者N-Array join 一起处理,而不是一个一个处理
搜索终止条件:找到了低于 Cost threshold 的Plan;超时;转换规则已用尽
引用:https://blog.bcmeng.com/post/starrocks-source-code-1.html
本文由 妖言君 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Apr 8, 2022 at 12:35 pm