starrocks QE的启动
QE 是一个实现了mysql协议的server.starrocks在原先的基础上实现了nio的mysqlserver 提高查询相应时间。
QE的启动涉及的类:
NMysqlServer:nio版本的mysql协议server
AcceptListener: 监听连接的Listener
ConnectScheduler: 连接调度器
ConnectProcessor:连接处理器
下面来看处理mysql连接的流程:
1 nMysqlServer的启动:
public boolean start() {
try {
server = xnioWorker.createStreamConnectionServer(new InetSocketAddress(port),
acceptListener,
OptionMap.create(Options.TCP_NODELAY, true, Options.BACKLOG, Config.mysql_nio_backlog_num));
server.resumeAccepts();
running = true;
LOG.info("Open mysql server success on {}", port);
return true;
} catch (IOException e) {
LOG.warn("Open MySQL network service failed.", e);
return false;
}
}通过XnioWorker 创建createStreamConnectionServer 通过acceptListener 接收连接请求和处理
AcceptListener 处理连接的函数如下:
1 接收连接
2 构建上下文并并从worker中获取线程处理当前的连接
3 进行验证
4 启动ConnectProcessor处理后续的SQL 请求
public void handleEvent(AcceptingChannel<StreamConnection> channel) {
try {
StreamConnection connection = channel.accept();
if (connection == null) {
return;
}
LOG.info("Connection established. remote={}", connection.getPeerAddress());
// connection has been established, so need to call context.cleanup()
// if exception happens.
NConnectContext context = new NConnectContext(connection);
context.setCatalog(Catalog.getCurrentCatalog());
connectScheduler.submit(context);
try {
channel.getWorker().execute(() -> {
try {
// Set thread local info
context.setThreadLocalInfo();
context.setConnectScheduler(connectScheduler);
// authenticate check failed.
if (!MysqlProto.negotiate(context)) {
throw new AfterConnectedException("mysql negotiate failed");
}
if (connectScheduler.registerConnection(context)) {
MysqlProto.sendResponsePacket(context);
connection.setCloseListener(streamConnection -> connectScheduler.unregisterConnection(context));
} else {
context.getState().setError("Reach limit of connections");
MysqlProto.sendResponsePacket(context);
throw new AfterConnectedException("Reach limit of connections");
}
context.setStartTime();
ConnectProcessor processor = new ConnectProcessor(context);
context.startAcceptQuery(processor);
} catch (AfterConnectedException e) {
// do not need to print log for this kind of exception.
// just clean up the context;
context.cleanup();
} catch (Throwable e) {
if (e instanceof Error) {
LOG.error("connect processor exception because ", e);
} else {
// should be unexpected exception, so print warn log
LOG.warn("connect processor exception because ", e);
}
context.cleanup();
} finally {
ConnectContext.remove();
}
});
} catch (Throwable e) {
if (e instanceof Error) {
LOG.error("connect processor exception because ", e);
} else {
// should be unexpected exception, so print warn log
LOG.warn("connect processor exception because ", e);
}
context.cleanup();
ConnectContext.remove();
}
} catch (IOException e) {
LOG.warn("Connection accept failed.", e);
}
}有两个重点是 connectScheduler.submit(context); 和 context.startAcceptQuery(processor);
其中的submit 启动了LoopHandler 线程不断地启动新的connectProcessor处理新进来的请求。
而startAcceptQuery 是为了调度ReadListener
public void startAcceptQuery(NConnectContext nConnectContext, ConnectProcessor connectProcessor) {
conn.getSourceChannel().setReadListener(new ReadListener(nConnectContext, connectProcessor));
conn.getSourceChannel().resumeReads();
}
ReadListener 重点方法还是 connectProcessor.processOnce();processOnce的中重点是dispatch()方法其实就是处理一条完整的SQL操作命令命令处理的重点代码:
private void dispatch() throws IOException {
int code = packetBuf.get();
MysqlCommand command = MysqlCommand.fromCode(code);
if (command == null) {
ErrorReport.report(ErrorCode.ERR_UNKNOWN_COM_ERROR);
ctx.getState().setError("Unknown command(" + command + ")");
LOG.warn("Unknown command(" + command + ")");
return;
}
ctx.setCommand(command);
ctx.setStartTime();
switch (command) {
case COM_INIT_DB:
handleInitDb();
break;
case COM_QUIT:
handleQuit();
break;
case COM_QUERY:
handleQuery();
ctx.setStartTime();
break;
case COM_FIELD_LIST:
handleFieldList();
break;
case COM_CHANGE_USER:
handleChangeUser();
break;
case COM_RESET_CONNECTION:
handleResetConnnection();
break;
case COM_PING:
handlePing();
break;
default:
ctx.getState().setError("Unsupported command(" + command + ")");
LOG.warn("Unsupported command(" + command + ")");
break;
}
}
走到这我们总结下,借助xnio的nio处理模型,我们接收到连接读取packet并将packet交给注册的AcceptListener进行连接处理的,根据不同的SQL命令执行不同的操作并将结果返回。
SQL解析
背景知识:
基本流程 词法解析 -》语法解析 -》 逻辑计划-》物理执行计划
starrocks的词法解析和语法解析是通过 jflex 与javacup完成的。
jflex
词法解析是通过在在jflex中定义关键字。
private static final Map<String, Integer> keywordMap = new LinkedHashMap<String, Integer>();
static {
keywordMap.put("&&", new Integer(SqlParserSymbols.KW_AND));
keywordMap.put("add", new Integer(SqlParserSymbols.KW_ADD));
keywordMap.put("admin", new Integer(SqlParserSymbols.KW_ADMIN));
keywordMap.put("after", new Integer(SqlParserSymbols.KW_AFTER));
keywordMap.put("aggregate", new Integer(SqlParserSymbols.KW_AGGREGATE));
keywordMap.put("all", new Integer(SqlParserSymbols.KW_ALL));
keywordMap.put("alter", new Integer(SqlParserSymbols.KW_ALTER));
keywordMap.put("and", new Integer(SqlParserSymbols.KW_AND));
......
}
tokenIdMap
tokenIdMap.put(new Integer(SqlParserSymbols.IDENT), "IDENTIFIER");
tokenIdMap.put(new Integer(SqlParserSymbols.COMMA), "COMMA");
tokenIdMap.put(new Integer(SqlParserSymbols.BITNOT), "~");
tokenIdMap.put(new Integer(SqlParserSymbols.LPAREN), "(");
tokenIdMap.put(new Integer(SqlParserSymbols.RPAREN), ")");
tokenIdMap.put(new Integer(SqlParserSymbols.LBRACKET), "[");
tokenIdMap.put(new Integer(SqlParserSymbols.RBRACKET), "]");
tokenIdMap.put(new Integer(SqlParserSymbols.LBRACE), "{");
tokenIdMap.put(new Integer(SqlParserSymbols.RBRACE), "}");
tokenIdMap.put(new Integer(SqlParserSymbols.COLON), ":");sql 词法分析是将SQL语句一个个分割成token sql
sql_parser_cup
cup中定义了语法
grant_user ::=
user_identity:user_id
{:
/* No password */
RESULT = new UserDesc(user_id);
:}
| user_identity:user_id KW_IDENTIFIED KW_BY STRING_LITERAL:password
{:
/* plain text password */
RESULT = new UserDesc(user_id, password, true);
:}
| user_identity:user_id KW_IDENTIFIED KW_BY KW_PASSWORD STRING_LITERAL:password
{:
/* hashed password */
RESULT = new UserDesc(user_id, password, false);
:}
| user_identity:user_id KW_IDENTIFIED KW_WITH IDENT:auth_plugin
{:
/* with auth plugin */
RESULT = new UserDesc(user_id, auth_plugin);
:}
| user_identity:user_id KW_IDENTIFIED KW_WITH IDENT:auth_plugin KW_AS STRING_LITERAL:auth_string
{:
/* with auth plugin and auth string, encrypted if auth string is password */
RESULT = new UserDesc(user_id, auth_plugin, auth_string, false);
:}
| user_identity:user_id KW_IDENTIFIED KW_WITH IDENT:auth_plugin KW_BY STRING_LITERAL:auth_string
{:
/* with auth plugin and auth string, plain text if auth string is password */
RESULT = new UserDesc(user_id, auth_plugin, auth_string, true);
:}
;比如上边grant的语句他定义了怎样的grant 语句是合法的。通过的语法解析便会生成相应的语法解析树也就是我们常说的AST.
AST解析完成后便需要生成逻辑计划。什么是逻辑计划,逻辑计划负责将抽象语法树转成代数关系。代数关系是一棵算子树,每个节点代表一种对数据的计算方式。 就是你得告诉我每一步这个数据需要怎么处理.就像下边这个图:
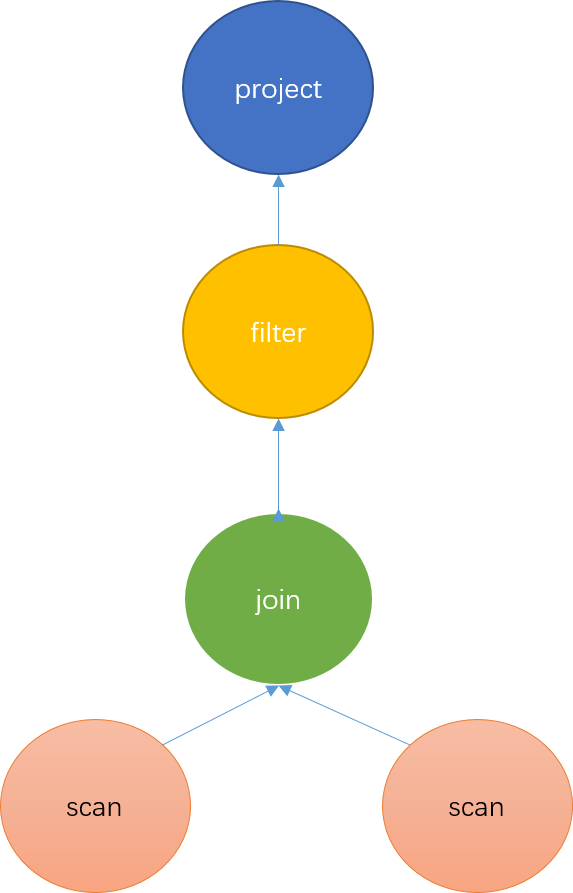
第一步扫描两张表的数据,第二步对数据进行join 第三步对数据进行过滤
物理计划
物理计划是在逻辑计划的基础上,根据机器的分布,数据的分布,决定去哪些机器上执行哪些计算操作。就是真正在每一台机器上要做什么操作。
Anltr
starrocks 在原来 jflex 和jcup的基础之上重新利用业界成熟的ANLTR4 引擎生成 SQL的词法和语法解析器
ANLTR 语法解析器的基本介绍可以参照:https://www.cnblogs.com/vivotech/p/15122322.html#fromHistory#fromHistory
SQL 执行优化
继续接着上文的handlerQuery函数
private void handleQuery() {
...
try {
stmts = com.starrocks.sql.parser.SqlParser.parse(originStmt, ctx.getSessionVariable().getSqlMode());
} catch (ParsingException parsingException) {
throw new AnalysisException(parsingException.getMessage());
} catch (Exception e) {
stmts = analyze(originStmt);
}
...
executor = new StmtExecutor(ctx, parsedStmt);
ctx.setExecutor(executor);
executor.execute();
}ConnectProcessor类的analyze方法:
input:String类型的 SQL 字符串
output:StatementBase类型的 AST 语法树
/ analyze the origin stmt and return multi-statements
private List<StatementBase> analyze(String originStmt) throws AnalysisException {
...
SqlScanner input = new SqlScanner(new StringReader(originStmt), ctx.getSessionVariable().getSqlMode());
SqlParser parser = new SqlParser(input);
try {
return SqlParserUtils.getMultiStmts(parser);
} catch
...
}
AST树状结构如图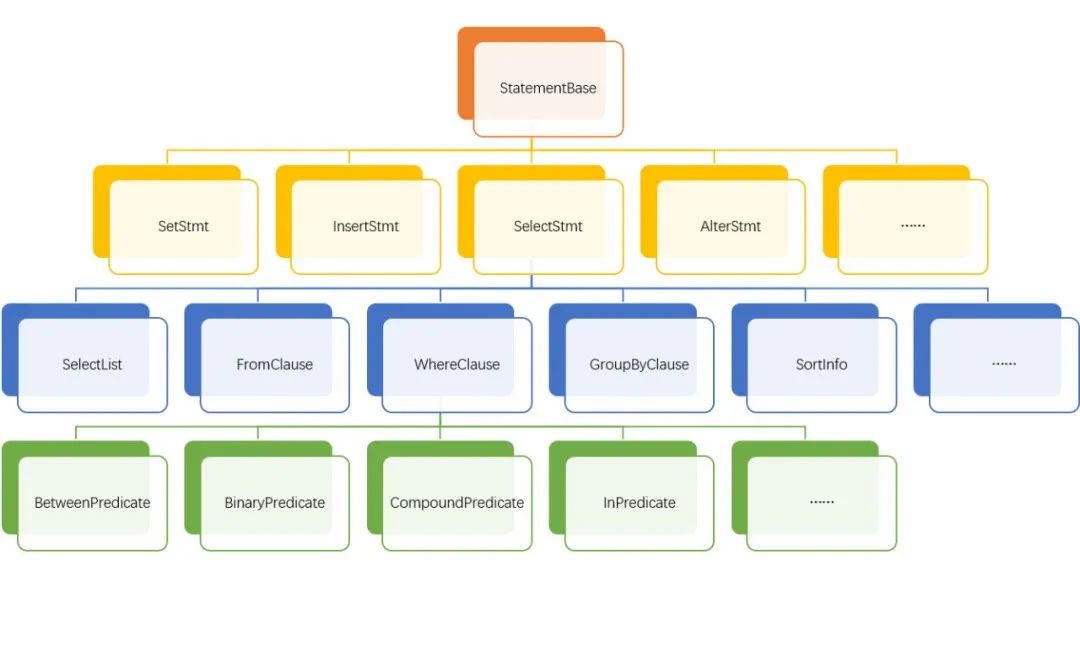
每一个节点都是一类statement 如 SelectStmt, InsertStmt, ShowStmt, SetStmt, AlterStmt, AlterTableStmt, CreateTableStmt 针对SQL的不同部分会进行相应的原语解析。
execute 生成logic plan
针对parse 完的statement进一步生成执行计划
public void execute() throws Exception {
execPlan = new StatementPlanner().plan(parsedStmt, context);
}
public ExecPlan plan(StatementBase stmt, ConnectContext session) throws AnalysisException {
Analyzer.analyze(stmt, session);
PrivilegeChecker.check(stmt, session);
if (stmt instanceof QueryStatement) {
...
ExecPlan plan = createQueryPlan(((QueryStatement) stmt).getQueryRelation(), session);
} else if (stmt instanceof InsertStmt) {
...
return new InsertPlanner().plan((InsertStmt) stmt, session);
} else if (stmt instanceof UpdateStmt) {
...
return new UpdatePlanner().plan(updateStmt, session);
}首先是对statement进行analyse 然后针对不同的语句创建不同的执行计划。queryplan insertplan and updateplan
Analyzer里针对不同的语句进行了关系的分析从而生成相应relation关系图。
针对Query的analyzer QueryAnalyzer他主要做了一下事情:
1 关联SQL语句到相应的Cluster database Table
2 SQL 的合法性检查
3 SQL重写
4 Table 和 Column 的别名处理
5 Tuple, Slot, 表达式分配唯一的 ID
6 函数参数的合法性检测
7 表达式替换
8 类型检查,类型转换
Analyzer类的analyze方法:
Input:StatementBase类型的 AST 语法树
output:Relation类型的关系代数
public class SelectRelation extends QueryRelation {
private final Expr predicate;
private final List<Expr> groupBy;
private final List<FunctionCallExpr> aggregate;
...
// 子Relation
private final Relation relation;
private Map<Expr, FieldId> columnReferences;
}select from a join (select from xx where a<10)b on a.id=b.id 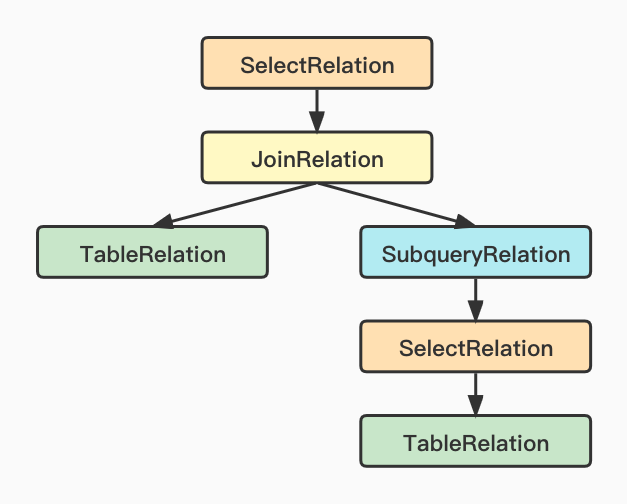
createQueryPlan 是针对relation 进一步生成逻辑执行计划:
1 构建逻辑执行计划
2 SQL优化
3 分片执行计划
QueryRelation query = (QueryRelation) relation;
List<String> colNames = query.getColumnOutputNames();
//1. Build Logical plan
ColumnRefFactory columnRefFactory = new ColumnRefFactory();
LogicalPlan logicalPlan = new RelationTransformer(columnRefFactory, session).transformWithSelectLimit(query);
//2. Optimize logical plan and build physical plan
Optimizer optimizer = new Optimizer();
OptExpression optimizedPlan = optimizer.optimize(
session,
logicalPlan.getRoot(),
new PhysicalPropertySet(),
new ColumnRefSet(logicalPlan.getOutputColumn()),
columnRefFactory);
//3. Build fragment exec plan
/*
* SingleNodeExecPlan is set in TableQueryPlanAction to generate a single-node Plan,
* currently only used in Spark/Flink Connector
* Because the connector sends only simple queries, it only needs to remove the output fragment
*/
if (session.getSessionVariable().isSingleNodeExecPlan()) {
return new PlanFragmentBuilder().createPhysicalPlanWithoutOutputFragment(
optimizedPlan, session, logicalPlan.getOutputColumn(), columnRefFactory, colNames);
} else {
return new PlanFragmentBuilder().createPhysicalPlan(
optimizedPlan, session, logicalPlan.getOutputColumn(), columnRefFactory, colNames);
}其中optimizer是重要的部分,谓词下推等操作都是在这里边进行。先来看逻辑执行计划的构建:
LogicalPlan logicalPlan = new RelationTransformer(columnRefFactory, session).transformWithSelectLimit(query);这部分是将relation转换为对数据的operator的操作。
select from a join (select from xx where a<10)b on a.id=b.id 转换成的operator才做图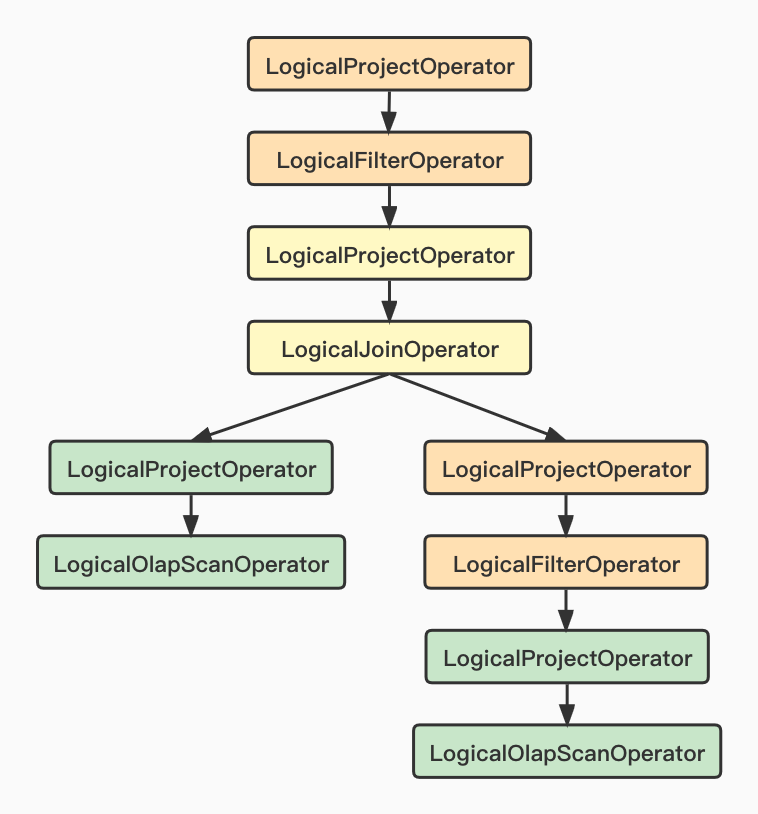
本文由 妖言君 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Apr 8, 2022 at 10:22 am