从数据层级看flink 提供了四级的数据流操作,底层是有状态流处理。上层是dataset 和datastream
dataset 是有界流的api,datastream是无界流的api.再往上就是table API 和SQL 更高级的操作。
数据流
数据流的编程和job graph对应的关系如图:
主要包含以下几个步骤的操作:
source->tranformation->sink
当然这是单线程的情况,多线程的情况入下:
在数据处理的过程中会有部分算子的操作需要进行数据之间的交换。需要重新分布的几个算子如下:
keyBy(), broadcast(), rebalance() 这些会打乱数据在不同线程中的分布。
时间
流处理包含几个不同的时间
event_time: 事件时间
process_time: 处理时间
状态
状态的存在是因为有些数据操作需要跟历史的数据产生关联,比如统计5分钟内的总数,甚至是更复杂的一些处理。由于flink是多进程分布在不同机器进行的,因此需要根据key 来做state的存储。
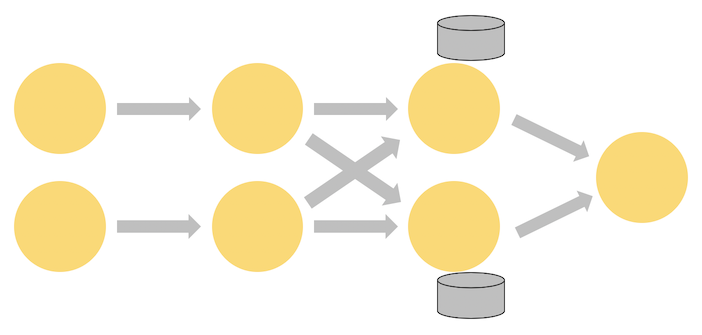
像下面的第三步的操作就是进行state的操作,在第二步打乱了数据之间的顺序。状态的存储有memstate,rockdbstate,hdfsstate 后续我们会详细解说。
本文由 妖言君 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Feb 22, 2021 at 11:27 am